Loading 261GB of Reddit Comments into Snowflake
I used to load reddit comments onto BigQuery, now it’s time to upgrade my pipelines to Snowflake — and to share some of the nice surprises I found. Let’s get started with 261GB of them.

Loading and analyzing reddit comments in Snowflake is fun, and a great way to show its powers. These are some of the Snowflake features that delighted me, that I didn’t get with BigQuery:
- Working with semi-structured data in Snowflake is fast, easy, and fun.
- Snowflake understands JSON objects on load, and optimizes the syntax and storage for them — without the need to predefine a schema.
- Snowflake stores data compressed — in this case with a ratio better than 1:10 compared with the original files.
- Snowflake supports advanced SQL syntax for recursive queries — which is awesome to analyze threaded comments.
- Snowflake supports not only JavaScript UDFs, but also Java UDFs and external functions — which opens up a world of possibilities within the database.
Download and recompress into S3
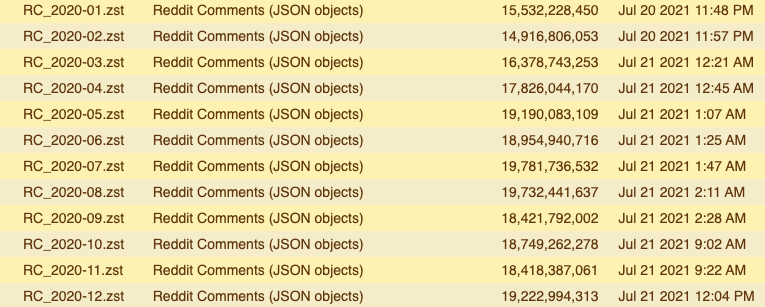
Jason Baumgartner shares through PushShift.io billions of reddit comments and submissions. These are the archives that I’ll load into Snowflake, but first I need to download them.
For example, all the reddit comments from December 2020 live in a 19GB file:
Download
The first problem to get these files is how slow this server’s bandwidth is. Each file is taking me around 17 hours of downloading on a VM in AWS EC2:

Instead of downloading all these files for hours, we could share the results of this whole process within Snowflake and the Data Cloud — but someone needs to get this process started. So let’s keep working on this.
By the way, I launched a t4g.medium instance on EC2 to pull this off. These Arm-based AWS Graviton2 “instances accumulate CPU credits when a workload is operating below the baseline threshold and utilize credits when running above the baseline threshold”. This means the instance “accumulates” CPU power while the files are being downloaded, and then these “credits” are used to make the re-compression part way faster than the baseline.
As an implementation note: I tried the GCP Storage Transfer Service to download these files. An advantage to this approach is that you don’t need to deploy an instance to perform these lengthy file transfers, but it kept failing.

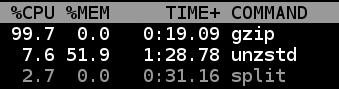
Re-compress
The next challenge is that this big 18GB .zst file needs to be split into smaller .gz compressed files. After a little bit of research, this was my chosen CLI pipeline to pull this off in one line:
unzstd --long=31 -c ../RC_2020-12.zst - | split -C 1000000000 -d -a4 - reddit_comments_202012_ --filter='gzip > $FILE.gz'# https://stackoverflow.com/a/68718176/132438
Push to S3 and Snowflake
Because I chose a Graviton2 VM, the easiest way to make the files available to Snowflake was to move them to S3 (snowsql is not yet available on Arm):
aws s3 cp --recursive . s3://my-s3/202108/reddit/Then Snowflake can see these files by following the docs to create a storage integration:
use role accountadmin;create or replace storage integration s3_int_reddit
type = external_stage
storage_provider = s3
enabled = true
storage_aws_role_arn = 'arn:aws:iam::4815162342:role/my_role'
storage_allowed_locations = ('s3://my-s3/');desc integration s3_int_reddit;grant create stage on schema public to role sysadmin;
grant usage on integration s3_int_reddit to role sysadmin;use role sysadmin;create or replace stage my_ext_stage_reddit
url='s3://my-s3/'
storage_integration = s3_int_reddit;
list @my_ext_stage_reddit;
Now we can ingest these .json.gz files from S3 into a Snowflake native table:
create or replace table reddit_comments_sample(v variant)
;copy into reddit_comments_sample
from @my_ext_stage_reddit/202108/reddit/
file_format = (type=json)
;
What’s interesting about this table on Snowflake:
- Snowflake natively understands json objects, and stores them in a semi-columnar format.
- Snowflake auto-detect files compressed with gzip.
- The destination table has only one column that will store the JSON object with the
VARIANTtype. - Snowflake stores data compressed. For example, 140GB of raw json encoded comments use only 11.8GB of storage once in Snowflake.
Snowflake offers built-in functions and SQL extensions for traversing, flattening, and nesting of semi-structured data, with support for popular formats such as JSON and Avro. Automatic schema discovery and columnar storage make operations on schema-less, semi-structured data nearly as fast as over plain relational data, without any user effort. White Paper for SIGMOD (by Snowflake founders Thierry, Benoit and Team, 2016)
Fun with SQL
Once the comments are ingested into our Snowflake table, we can start having fun with SQL.
While writing this I’m still waiting for the unzstd+split+gz process to finish, so I ran these tests with only the first 140 gzip files (each with 100GB of comments, per our instructions to split).
Let’s see how many comments and time ranges this table contains:
select count(*) comments
, min(v:created_utc)::timestamp since
, max(v:created_utc)::timestamp until
from reddit_comments_sample;# 84,448,007 COMMENTS
# 2020-11-30 16:00:00.000 SINCE
# 2020-12-14 04:40:50.000 UNTIL
This query ran in 0.116 seconds, and you can immediately notice some convenient SQL syntax in Snowflake:
vis the name we gave to the column containing ourvariant.:created_utcis the name of the key that reddit chose to contain the timestamp in seconds since epoch. Snowflake allows us to navigate JSON objects easily with this syntax.::timestampis how we cast in Snowflake the UNIX time to a regular timestamp. This syntax is easy to type and understand.
To see all the keys in each reddit JSON comment object, we can use some SQL to flatten it:
select key, value
from (
select *
from reddit_comments_sample
limit 1
), table(flatten(v))
limit 100;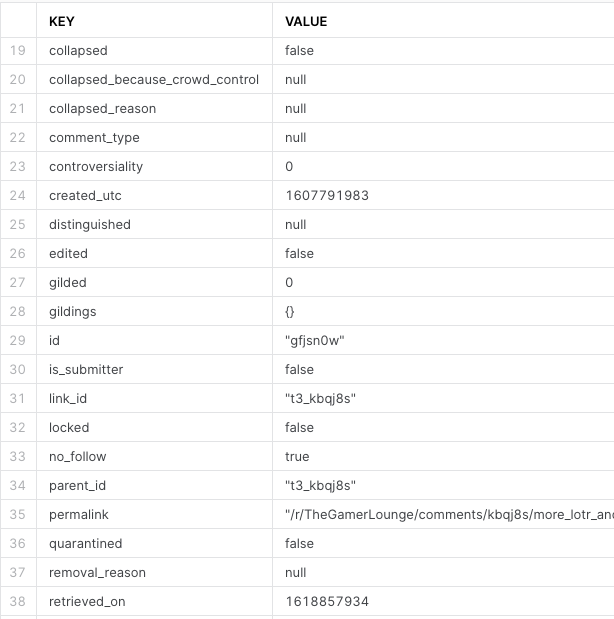
We can write a query like this to count the number of comments for the most popular subreddits and the average comment score:
select v:subreddit::string sub, count(*) c, avg(v:score) avg_score
from reddit_comments_sample
group by 1
order by 2 desc
limit 10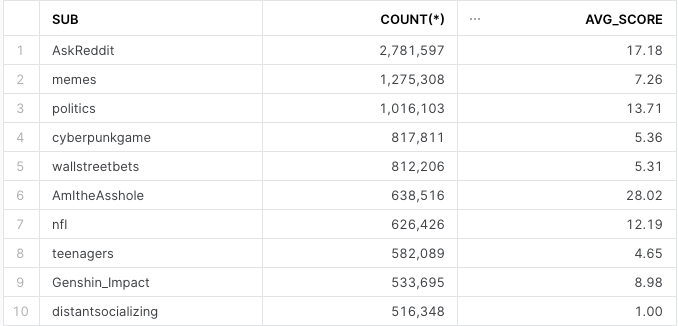
And we can get a quick visualization within the new Snowflake UI (Snowsight):
This query to look for the subreddits with most awards is interesting:
select v:subreddit::string sub
, count_if(v:all_awardings > '[]') count_awards
, count_awards/count(*) ratio_with_awards
, sum(v:all_awardings[0]:coin_price) sum_coin_price
, avg(v:all_awardings[0]:coin_price) avg_coin_price
from reddit_comments_sample
group by sub
order by 2 desc
limit 100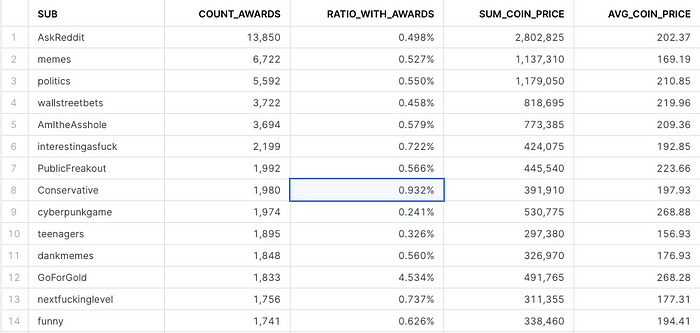
What’s interesting in the query syntax:
v:all_awardings[0]:coin_priceshows how to navigate the original JSON object with SQL — as Snowflake manages to navigate and store semi-structured data smartly.count_awardsgets defined as a column first, and then this alias can be laterally used in the same select to getcount_awards/count(*).
And instead of writing a query, Snowsight lets us quickly re-sort to find the subreddits within this top 100 with the highest chance of comment gold:
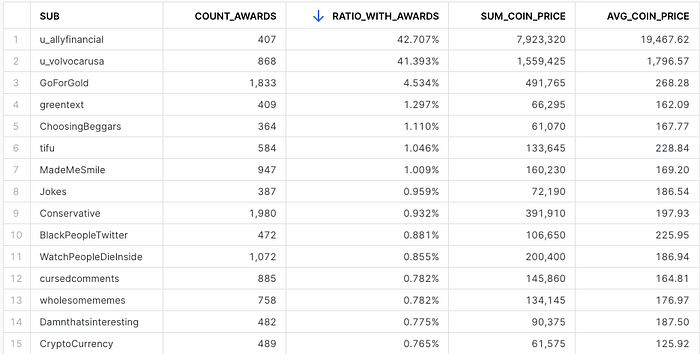
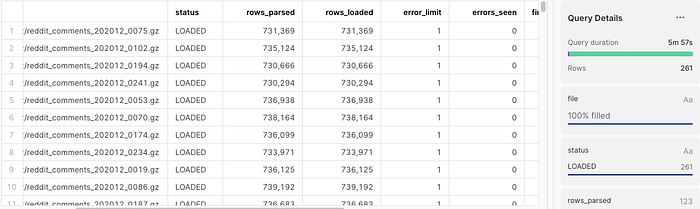
Update: Now the whole month is in
Once I got the whole month out of pushshift.io, I was able to load it. Total storage in Snowflake is 19.9GB, compared to 261GB uncompressed. That’s a 1:13 compression ratio. It took 6 minutes to ingest 191 million comments using an L warehouse:
create or replace table reddit_comments_202012(v variant)
cluster by (v:subreddit::string, v:created_utc::timestamp)
;copy into reddit_comments_202012
from @my_ext_stage_reddit/202108/reddit/
file_format = (type=json)
;
Next steps
As seen above, once the data is in Snowflake, we can have fun!
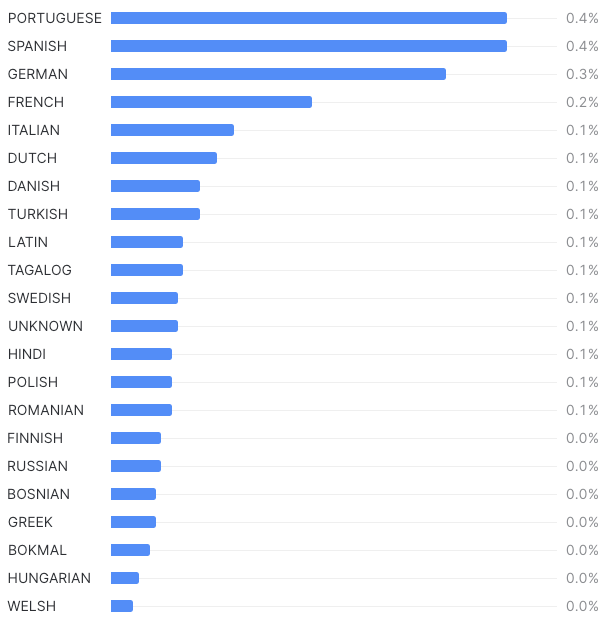
Language detection with Java UDFs
For example, an experiment detecting the language of each comment with a Java UDF over some random 20,000 comments shows us the most common languages on reddit — other than English:
Recursive queries
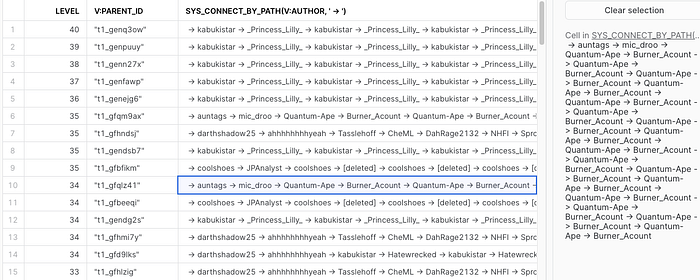
Snowflake supports the CONNECT BY syntax to traverse trees. For example, to recursively find the longest threads on /r/dataisbeautiful you can use this query:
with data as (
select *
from reddit_comments_sample
where v:subreddit = 'dataisbeautiful'
)select *
from (
select level, v:parent_id, sys_connect_by_path(v:author, ' -> ')
from data
start with substr(v:parent_id, 1, 3) = 't3_'
connect by prior v:id = substr(v:parent_id, 4)
)
order by level desc
limit 100
Dynamic data masking and more
Let’s save some fun for future posts. I’ll do my best to load the full reddit corpus from PushShift.io into Snowflake, and share more interesting use cases!
Want more?
- Try this out with a Snowflake free trial account — you only need an email address to get started.
I’m Felipe Hoffa, Data Cloud Advocate for Snowflake. Thanks for joining me on this adventure. You can follow me on Twitter and LinkedIn. Check reddit.com/r/snowflake for the most interesting Snowflake news.
